Pogo - distributed supervisor for Elixir
Typical architecture of systems written for Erlang VM consists of a top-level process, known as a supervisor, which spawns and monitors child processes that can either act as workers or be supervisors themselves. Such hierarchical process structure is known as supervision tree. Supervisors are fundamental builing blocks of fault-tolerant applications and embodiment of the famous “let it crash” philosophy which, in case of a serious failure, prefers that a process be fully restarted (by its supervisor) to a known good state rather than perform overextensive error handling. Supervisor processes are responsible for managing the lifecycle of their child processes, which includes starting, termination, monitoring and possibly restarting them when they crash.
Ease of building distributed systems is another main selling point of Erlang VM. All it takes for processes running on different nodes to communicate with each other is to ensure that their nodes are connected in a cluster. From code perspective, sending a message to a process running on another node is no different than sending it locally.
While supervision and distribution are first-class citizens of the VM, the standard library doesn’t provide a complete solution to the problem of process supervision in distributed environment. This article discusses why and how to use a distributed supervisor and demonstrates pogo library, developed at Telnyx, that provides one for Elixir applications.
What is a distributed supervisor
Unlike a typical supervisor, distributed supervisor is not a single process. It is many local supervisors running on different nodes, working in coordinated fashion. It abstracts away the complexity of scheduling and monitoring processes in distributed environment.
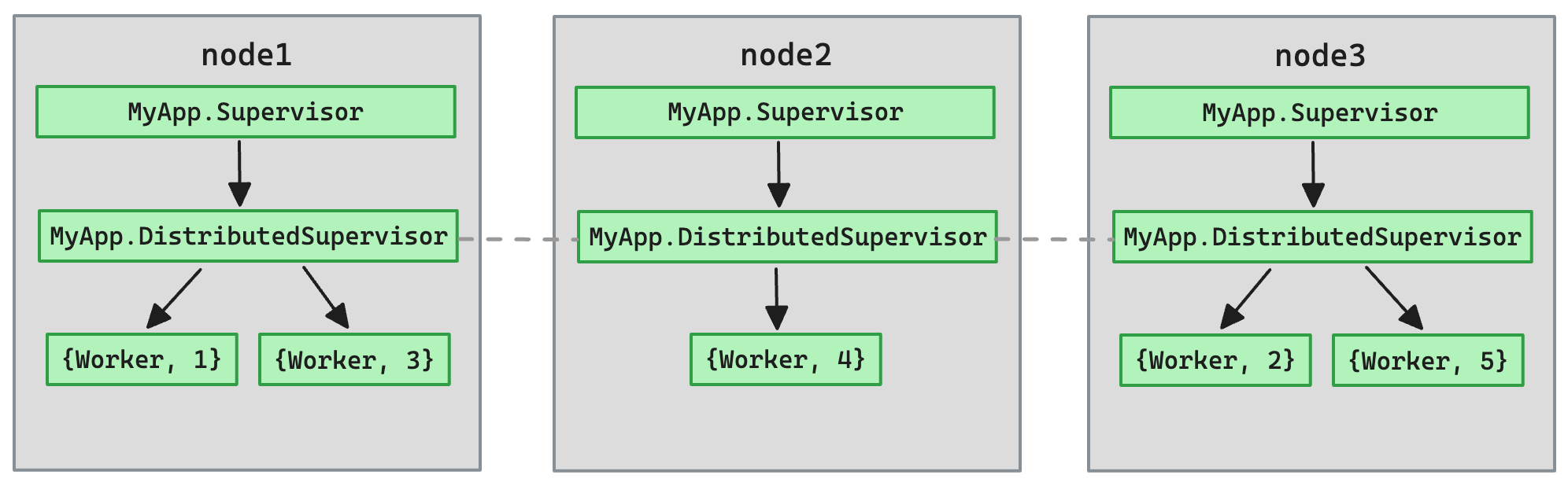
Scheduling child processes
When scheduling a process with a distributed supervisor no assumptions can be made about which node will actually start it, the only guarantee we get is that it will run “somewhere” in the cluster. Internally, pogo builds a consistent hash ring consisting of all participating nodes, calculates the search key by hashing the child process’ spec and determines which node in the ring “owns” the key. The local supervisor running on that node will then manage the process.
As a natural consequence of this approach, load will be spread over the cluster. Nodes participating in the ring own equally-sized keyspaces, so should theoretically have equal probabilities to be assigned a child process.
Synchronization
Each local supervisor periodically synchronizes with the cluster, inspecting cluster memberships and recalculating hashes. When local supervisor detects that it runs a child process that should be assigned to another node, that process is terminated with the assumption that it will be started on correct node when that node synchronizes.
Note that changes in cluster membership are automatically reflected in the structure of the node ring. When a node is added or removed, it is very likely that some child processes will get rescheduled to other nodes. Whether this behaviour is desired depends on the use case, of course, but it’s crucial to take it into account, especially when running the application in an unreliable network or with autoscaling.
Pogo has a configuration option to control how often synchronization happens. It can be set to a higher value in unstable networks to minimize the effects of aggressive rescheduling.
Pogo.DynamicSupervisor.start_link(sync_interval: 5_000)
Another important observation is that it is possible for a child process to be simultaneously running on multiple nodes, at least briefly. When rescheduling, the new node may be first to synchronize and start the child process before the old node terminates it. The consistency is eventually restored after full synchronization cycle.
Internal state
To maintain cluster-wide state, pogo uses battle-tested distributed named process groups available in Erlang’s standard library - :pg module1. It differs in this aspect from other similar libraries, like swarm2 or horde3. Pogo-based supervisors are completely reliant on process groups, they do not attempt to send any messages to each other.
When a local supervisor receives a request to start a child process via start_child/2, instead of starting it immediately, it propagates that request through process groups to supervisors running on other nodes. Termination of child processes via terminate_child/2 works in the same way. These requests are processed by local supervisors when they perform synchronization; once started, child process information is again propagated using process groups.
With :pg, process groups can be organised into named scopes that are completely independent of each other. It allows us operate multiple distributed supervisors in a single application, differing in configuration or even node memberships.
CAP theorem
In short, CAP theorem4 states that in the presence of network partition a distributed system can guarantee either consistency or availability, but not both. It should be now clear that pogo guarantees availability.
When network partition happens, our application will basically operate in two (or more) separated clusters, with each cluster running their own distributed supervisor on available nodes (even if it’s only a single node). Previously scheduled child processes will now be duplicated. Once network connectivity is restored, the clusters will merge and extraneous child processes will be terminated.

When to use distributed supervisor
Distributed supervisor is a good fit for clustered applications that need to effortlessly spread the load over available nodes while preserving all the benefits of typical Elixir’s Supervisor or DynamicSupervisor.
Real world example
The example below is based on one of the services we have at Telnyx. Its role is to monitor media servers, collect their metrics and expose them for other services to consume. Telnyx’s telephony platform runs across a global multi-cloud network and this service is deployed in multiple regions with multiple instances per region for redundancy and load distribution. For brevity, the code responsible for clustering of nodes is omitted5.
At startup, each node starts its own local supervisor under application’s supervision tree. As you can see, scope option is set to name of the region where the node is located, so our application effectively runs multiple distributed supervisors, one per region6.
Each local supervisor defines the same list of initial child processes to start under distributed supervisor, but these processes will of course be started only once per region, on their assigned nodes.
defmodule Monitor.Application do
use Application
def start(_type, _args) do
pogo_opts = [
name: Monitor.DistributedSupervisor,
scope: get_region(),
children: [
{Monitor.ServiceDiscovery, "media-server"},
{Monitor.ServiceDiscovery, "media-server-canary"}
]
]
children = [
{Pogo.DynamicSupervisor, pogo_opts}
#... other children
]
opts = [strategy: :one_for_one, name: Monitor.Supervisor]
Supervisor.start_link(children, opts)
end
end
In our case these initial children are service discovery processes for media servers (both default and canary versions). They constantly watch Consul for registrations and unregistrations of media-server and media-server-canary service instances and respectively start or stop probing processes for each discovered media server instance.
defmodule Monitor.ServiceDiscovery do
use GenServer
# ...
def handle_info({:register, service_id}, state) do
# new media server instance discovered, start probing process for it
Pogo.DynamicSupervisor.start_child(
Monitor.DistributedSupervisor,
{Monitor.Prober, service_id}
)
{:noreply, state}
end
def handle_info({:unregister, service_id}, state) do
# media server instance was unregistered, stop its probing process
Pogo.DynamicSupervisor.terminate_child(
Monitor.DistributedSupervisor,
{Monitor.Prober, service_id}
)
{:noreply, state}
end
end
That’s it. We need only one service discovery process per region for each service type we want to monitor and we need only one prober for each monitored service instance. Both size of the cluster and health of individual instances of monitoring service are transparent to us7, because pogo does all the dirty work. The load is spread over available nodes and if one of them goes down its local processes will be automatically redistributed to healthy nodes.
Footnotes
-
See Distributed named process groups in Erlang’s official docs. ↩
-
Swarm uses Interval Tree Clock. ↩
-
Horde uses ∂-CRDT and also provides distributed registry. ↩
-
Read about CAP theorem on Wikipedia. ↩
-
If you’re interested, we use Consul for service discovery and libcluster. ↩
-
Pogo takes advantage of the fact that process groups can be organized in multiple scopes that are completely independent of each other, simply by passing scope argument to
:pgfunction calls. ↩ -
Obviously we need to make sure there is at least one healthy node per region, but this is an operational problem. ↩